An open source tool for analyzing the structure and internals of npm packages.
It’s ok to duplicate code!
Sometimes the software engineering rules and best practices we live by become the very things that slow us down and we have to break them in order to make progress.
Adding the lint functionality was one of those moments.
At the time, the package analyzer was in great shape, no code duplication, clear boundaries, solid tests and most importantly useful. But the lint functionality needed capabilities the system wasn’t yet designed for. Doing it “the right way” would have meant touching unrelated parts of the codebase, inventing abstractions prematurely and carrying that complexity forward, slowing things down.
What I wanted instead was to build the lint functionality in isolation, so I can figure out things as I go and then integrate it later with a clearer understanding. But that meant duplicating parts of the existing system so I could hack around freely without affecting anything else. Best practices teach us that you should not do that. But that’s exactly what I did.
Because good engineering is as much about writing “clean” code as it is about delivering value.
The last thing I want is to write code that doesn’t provide value. And you avoid that by not blindly following best practices. Being too dogmatic about how the code needs to be gets in the way of learning, experimenting and delivering value.
I now could merge the lint functionality back into the main system and delete the duplication. Here are the key changes that made this integration possible.
Simplified Attachments
The first hurdle in implementing the lint functionality was the way Attachments worked.
Attachments allow you to attach arbitrary metadata to your dependency tree during lookup.
I’ve used it in the past to get the download numbers between 2 packages.
They looked like this:
export interface IAttachment<K extends string, T> { readonly key: K; readonly name: string; apply: (args: IApplyArgs) => Promise<T>;}A simple object with 3 properties: A key under which you can query the data later via .getAttachmentData(...). A name attribute for logging and finally a function that retrieves and returns the data.
While I always thought the current implementation is a tad bit too complicated, like the name attribute, which was well intentioned to provide more human readable logging, it didn’t turn out to provide great value.
Far more serious was the fact, that each Attachment sets its own name. This has 2 drawbacks
- You can’t use the same
Attachmenttwice, they will overwrite each other. - 2 completely different
Attachmentscould end up using the same name, causing conflicts.
This approach wouldn’t scale for the lint functionality, where yo ucould potentionally have hundreds of Attachments, so it was time for a change.
After the rework, all you need to provide now is a simple function:
export type AttachmentFn<T> = (args: IApplyArgs) => Promise<T>;The key will now be provided when you use the attachment and it’s up to you how you name it, making it possible to use the same attachment multiple times, thus eliminating any key clashes. The name attribute is gone altogether.
// oldthis.attachments = [new ReleaseAttachment(npmOnline)];// newthis.attachments = { releaseinfo: releaseAttachment(npmOnline) };
// usage remained the sameconst data = p.getAttachmentData("releaseinfo");A welcomed side effect of this code simplification was also that I could remove some wild TypeScript types that I had come up with.
Cleaned up report parameters
Next, I had to change how the report arguments worked.
They looked like this:
report( context: IReportContext, ...pkg: Args<PackageEntry, TAttachments> ): Promise<number | void>;The first parameter would be the context and the following parameters would be 1 or more dependency trees.
This was done because historically only 1 dependency tree was supported but then there was the need for a 2nd to be able to do comparisons. The easiest way back then was to implement it via the rest operator.
However for the lint functionality, 1 check would constitute 1 pkg entry as they could have different attachments etc. So e.g. if I define 3 checks then the report method would receive 3 dependency trees:
report(context, dependencyTreeCheck1, dependencyTreeCheck2, dependencyTreeCheck3);I didn’t know how this would scale with more checks, also I didn’t like how the context was the first argument, these things usually come later.
So I took the opportunity and changed the signature to look like this:
report(pkgs: Args<PackageEntry, TAttachments>, context: IReportContext): Promise<number | void>;Now the dependency trees are delivered as an array in the first argument and the 2nd parameter is now the context. There are no more than 2 parameters, ever.
Again, I could delete some wild TypeScript types that I had to come up with due to using the rest operator.
Per Package Configs
The final and most crucial change to make the lint functionality work was allowing each package to have its own configuration. Traditionally attachments and lookup depth were set once on the report level and thus shared by all specified packages. It’s not possible to define separate attachments for each package. This however is needed to make the lint functionality truly useful by allowing lint checks to bring their own attachments in order to create sophisticated checks.
Now, reports are configured via a new IReportConfig array allowing to specify different attachments within a single Report.
export interface IReportConfig<TAttachments extends Attachments = Attachments> { pkg: [name: string, version?: string]; type?: "dependencies" | "devDependencies"; depth?: number; attachments?: TAttachments;}The lint functionality
With everything in place, flexible attachments, scalable report function and per package configs, I could now merge the temporary linter service back into the main system and delete a lot of duplicated code. It’s always satisfying to remove more code than you add in a single commit while retaining the same functionality 😊
Pending a more detailed introduction later, this is how the lint functionality currently looks:
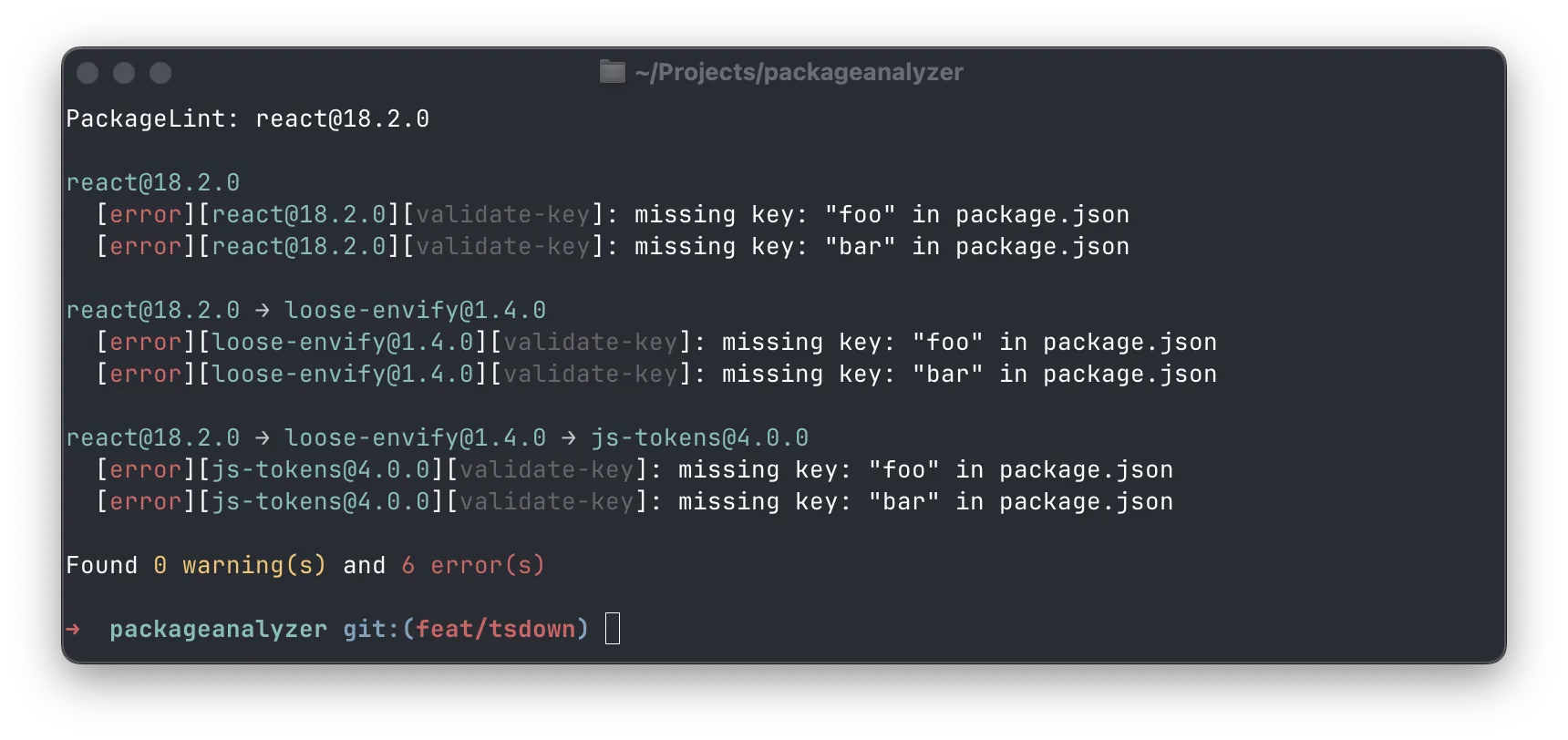
Here’s how you can implement a rule that detects if a package is deprecated:
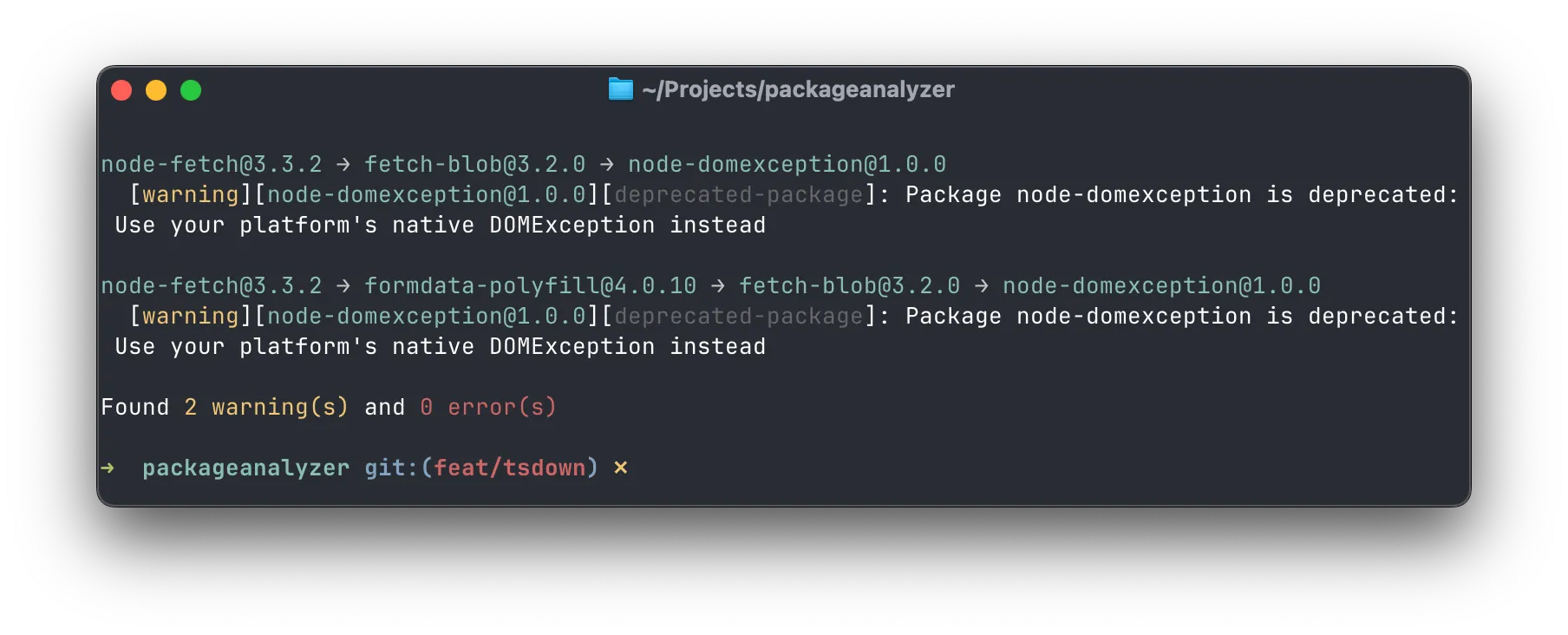
// lint config file
export default { rules: [ [ "warning", { name: "deprecated-package", check: pkg => { if (pkg.deprecatedInfo.deprecated) { return `Package ${pkg.name} is deprecated: ${pkg.deprecatedInfo.message}`; } } } ] ]};Checking the popular node-fetch package with ~70 million weekly downloads will give you the following output:
What’s next
Code wise there’s only 1 thing that I want to add before a possible 1.0 release and that is Jiti.
It’s a battle tested library to load config files. Currently, loading the lint config file is homegrown. Jiti allows for more flexibility and can also directly load .ts configs.
Also with that many changes lately, the documentation needs updating. Maybe I’ll take the opportunity and also move the documentation from Docusaurus to Starlight. Nothing wrong with Docusaurus except that I don’t use it nowadays in favor of Starlight.
Lastly, the project setup now also needs some love, it basically went unchanged after I set it up many years ago. A monorepo now makes a lot of sense and so is adding proper changelogs. tsdown also looks like a great library for publishing. All in all releasing a new version should be simple and come with a great developer experience for consumers via changelogs.